Jonas-Taha El Sesiy
Software Engineer

All views expressed are my own and not affiliated with current or former employers. Unless otherwise mentioned in the post, all projects are side projects which I work on on weekends and evenings.
Kubernetes: The client source IP preservation dilemma
A topic that’s been keeping me busy for a while now is how to ensure zero downtime when working in environments where the client source IP needs to be preserved. Let me elaborate on what the problem statement is exactly.
If you deploy an application on Kubernetes using a service type LoadBalancer, the cloud controller manager deploys a L4 load balancer in your respective cloud provider environment and usually allocates a public IP address for it. This allows users to effortlessly expose services to the public internet and common use cases include L7 load balancing solutions such as NGINX or Envoy. So far so good. Now if your application requires to know the real client IP this becomes a problem.
To understand the difficulty with this scenario, let’s have a look at how traffic routing works within Kubernetes. Each node runs kube-proxy which watches the API server for the addition or removal of service and endpoint objects. Without going into too much detail on user space, iptables and ipvs proxy modes, the basic idea is simple. When kube-proxy sees a new service, it will open up a new (random) port on each node for it. Now, when a client connects to the service IP, the proxy redirects traffic to its own port using some low-level routing logic, selects a backend and will proxy traffic from the client to it.
This works across nodes as the Kubernetes master assigns virutal IPs for services and kube-proxy keeps track of backends across nodes. For more info on this matter, I suggest taking a look at the outstanding official documentation here.
For the more visiual readers, here’s how this looks when using iptables proxy mode (most common).

Source: Kubernetes documentation
What you just read unfortunately doesn’t preserve the client source IP because kube-proxy replaces the source IP with a cluster internal IP due to the fact that the proxy randomly selects a backend to forward the traffic to. To prevent that, Kubernetes has a feature which explicitly tells kube-proxy to proxy requests only to local endpoints and not to other nodes. It’s as simple as setting the service.spec.externalTrafficPolicy to Local instead of the default Cluster. One thing to note here is that if there are no local endpoints, packets will be dropped. Again, more info on this can be found in the official docs.
Great, now our application is able to retrieve the actual client source IP instead of a cluster internal IP. This all sounds good until you have to think about upgrading your backend pods for the load balancer service, doing worker node ugprades or replacing entire nodepools.
Here’s why…
When a new service is added, the cloud provider’s load balancer backend pools is updated with the node IP and node port selected by kube-proxy. It then periodically checks whether the application is healthy using periodic probing. The healthchecks usually have to fail a certain retry count before the cloud provider decides to remove the ip from the load balancer pool. Now if kube-proxy doesn’t forward traffic to a different node and there’s a delay between the service endpoint removal and the cloud provider backend pool ip romal, we’re blackholing traffic.
Unlike adding a new service endpoint which automatically gets propagated to the cloud load balancer configuration, the removal of an endpoint does not. This could be seen as a design flaw of the cloud controller manager implementation but this is not a trivial problem to solve as the cloud provider has no way of knowing how downstream applications behave when connections are closed.
When presented with the aforementioned problem statement, solutions often propose adding the following two remediation items:
- Configure a
preStophook for the backend pods tosleepfor a certain period of time - Configure
terminationGracePeriodSecondsfor the pods to allow gracefully handle open connections before pod shutodwn
These are certainly important suggestions but only help in the case of a pod rolling update and only if either duration is at least as long as the cumulative time it takes for the health probes to fail and the backend pool to be updated. Since you might not have thought about this early on, you’re out of luck as changing it will trigger pod restarts.
At the heart of the issue is the fact that the node is registered to the load balancer and not individual pods. What complicates matters is the fact, that the service endpoint is removed regardless of a preStop hook or the terminationGracePeriodSeconds, see this issue for more context. Due to these circumstances it’s almost inevitable to end in a situation where new connections go nowhere which will cause a service disruption for a few unlucky users of your service (the endpoint is removed from the service while the existing pod on a node gracefully terminates and there may not be a second pod on the same node to serve the request).
Here’s a small diagram depicting the unfortunate situation.
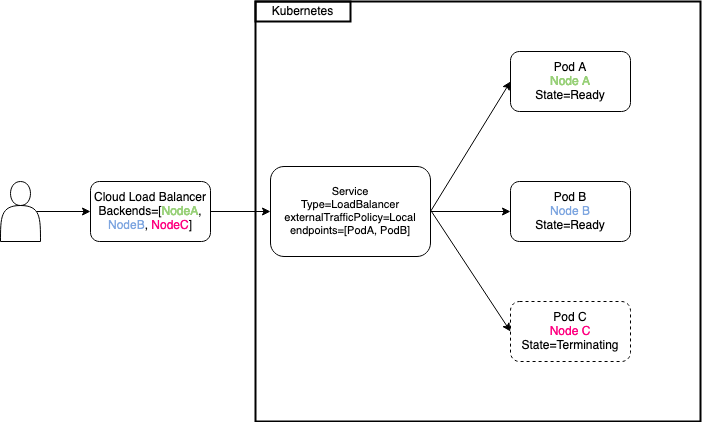
So what can you do you’re asking?
Well, until the the Kubernetes Enhancement Proposal (KEP-1669) is implemented which will dramatically improve the situation: not much. From what I know, you have to write some custom tooling to safely remove a node from your cloud provider load balancer outside of kubernetes since none of the existing primitives allow for zero downtime deployments.
Thanks for reading! It’s unfortunate that I can’t present you with a good solution but feel free to share your thoughts and reach out if you have any questions. Until next time ![]()
Tags: kubernetes, k8s, cncf, source ip, load balancer, kube-proxy, externalTrafficPolicy, graceful termination, zero downtime | Modify on GitHub